
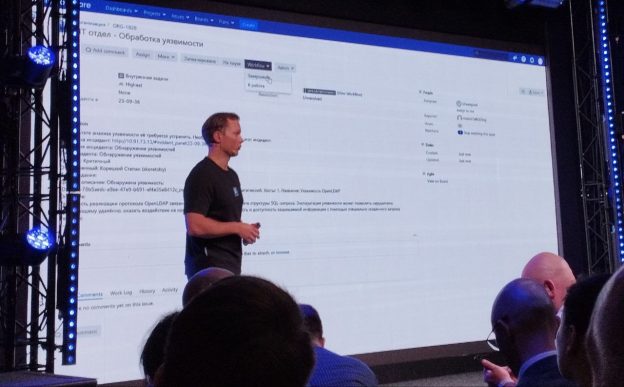
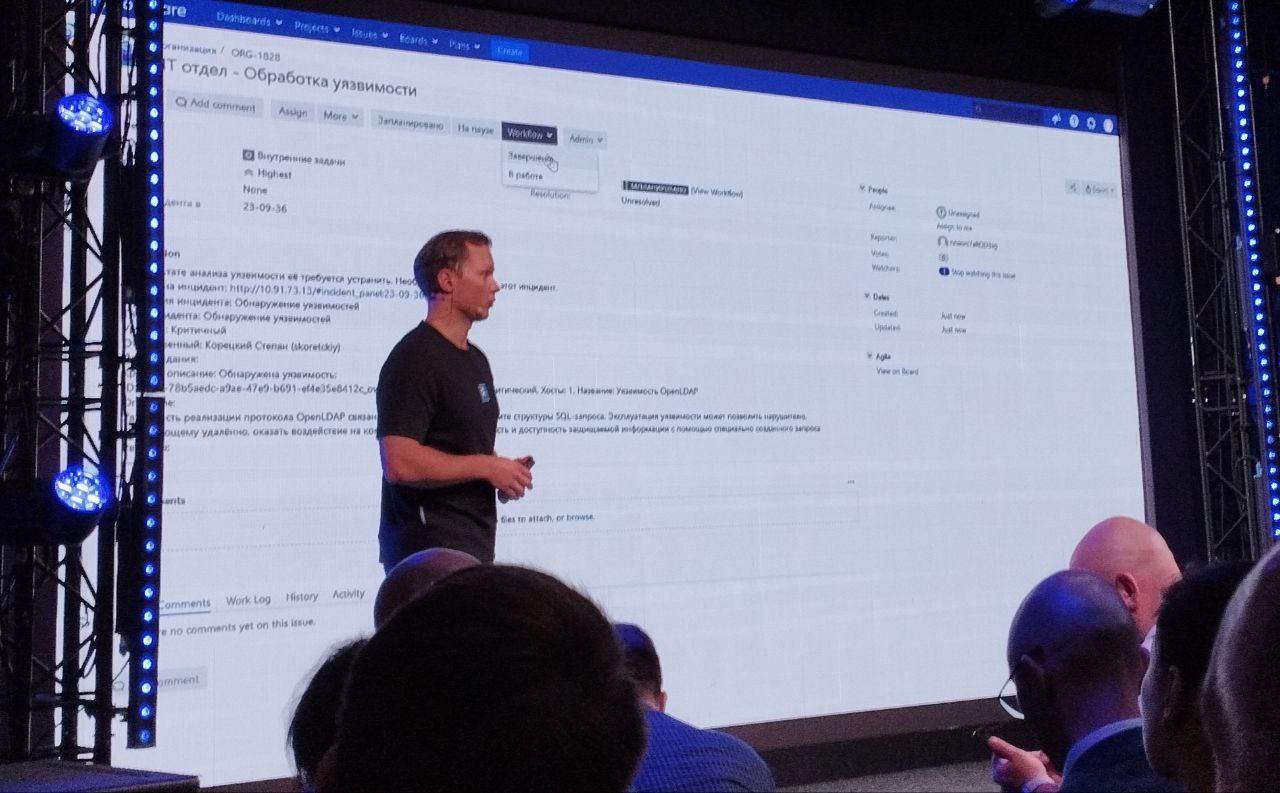
Ещё одно размышление после конференции R‑Vision, про таски на исправление уязвимостей. На этой теме был акцент и в основном выступлении про R‑Vision VM, и в кейсе НРД. Несмотря на то, что таски могут быть предметом долгих разбирательств IT и ИБ, имхо, таски должны быть. Почему?
1. Слова (как и дашборды, доступ для IT-шников в VM-систему, нотификации в почте/мессенджерах и прочее) к делу не пришьёшь. А тут формальная задачка. С критичностью, исполнителем и датой заведения. И для аудитов есть, что показать, и в случае инцидента пригодится. 😏
2. Вполне вероятно, что в организации уже внедрены процессы оценки эффективности работы подразделений на основе анализа статусов тасков, можно и исправление уязвимостей оценивать по аналогии.
3. Руководство ФСТЭК требует заводить таски. Можно, конечно, рассуждать об обязательности этого руководства, но если можно соответствовать, то лучше соответствовать. 😉
Какие это должны быть таски?
Имхо, это должны быть атомарные таски 1 актив и 1 уязвимость. Почему так?
1. Удобно отслеживать реальный прогресс. Иначе, если сделать связь один ко многим или многие ко многим, как абсолютно справедливо заметил в своём вчерашнем докладе Олег Кусеров, это будет приводить к большому количеству частично выполненных тасков.
2. Удобно менять критичность таска в случае изменения критичности уязвимости или актива.
3. Удобно делать интеграцию с системами управления уязвимостями. По сути таск просто привязывается к статусу уязвимости на активе.
Сколько таких тасков будет? Допустим, у нас для одного Linux хоста за месяц выходят 100 новых уязвимостей. Допустим, у нас 10000 Linux хостов в инфраструктуре. Получается миллион тасков за месяц. 12 миллионов в год. И это только Linux!
Отсюда следует:
1. Система для учёта тасков должна быть готова к таким объемам.
2. Вручную работать с такими тасками практически нереально.
Таски должны заводиться и закрываться автоматически по результатам детектирования уязвимостей.
✅ Таким образом ITшники, которые будут выполнять регулярный патчинг своих систем, возможно вообще без оглядки на продетектированные уязвимости, будут, в целом, автоматически соответствовать требованиям по исправлению уязвимостей и будут молодцы. 👍
❓А те ITшники, которые считают, что полное регулярное обновление им не подходит, смогут разбираться с каждой уязвимостью отдельно и тем способом, который сочтут нужным. Включая их ручную обработку. 🤷♂️ Может в процессе они скорректирую свои взгляды относительно регулярных обновлений. 😏



