
Коллеги из R-Vision представили на днях новую версию системы управления уязвимостями R‑Vision VM 6.1. Резюме маркетологов R-Vision: "в релизе особое внимание было уделено тому, что важно в ежедневной работе: ускорении поиска уязвимостей, гибкой приоритизации и автоматизации рутинных процессов".
Подробности и демо, видимо, стоит ожидать на вебинаре 24 марта и на конференции R‑EVOlution 9 апреля.
В пресс-релизе R-Vision сделали акцент на следующие фичи:
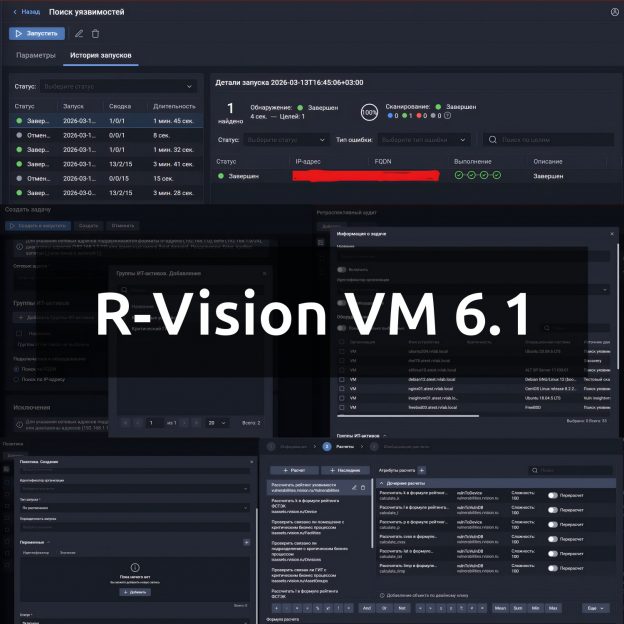
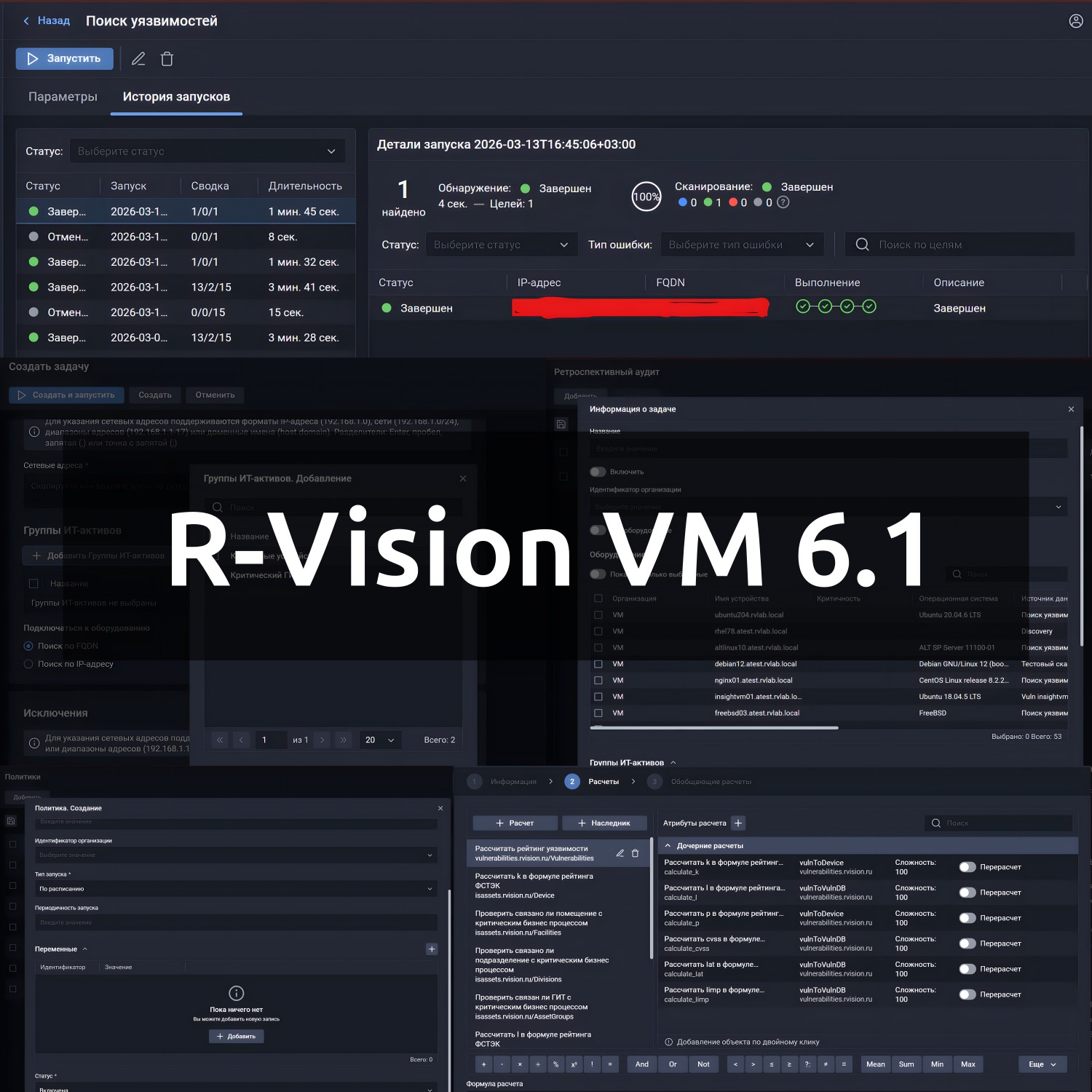
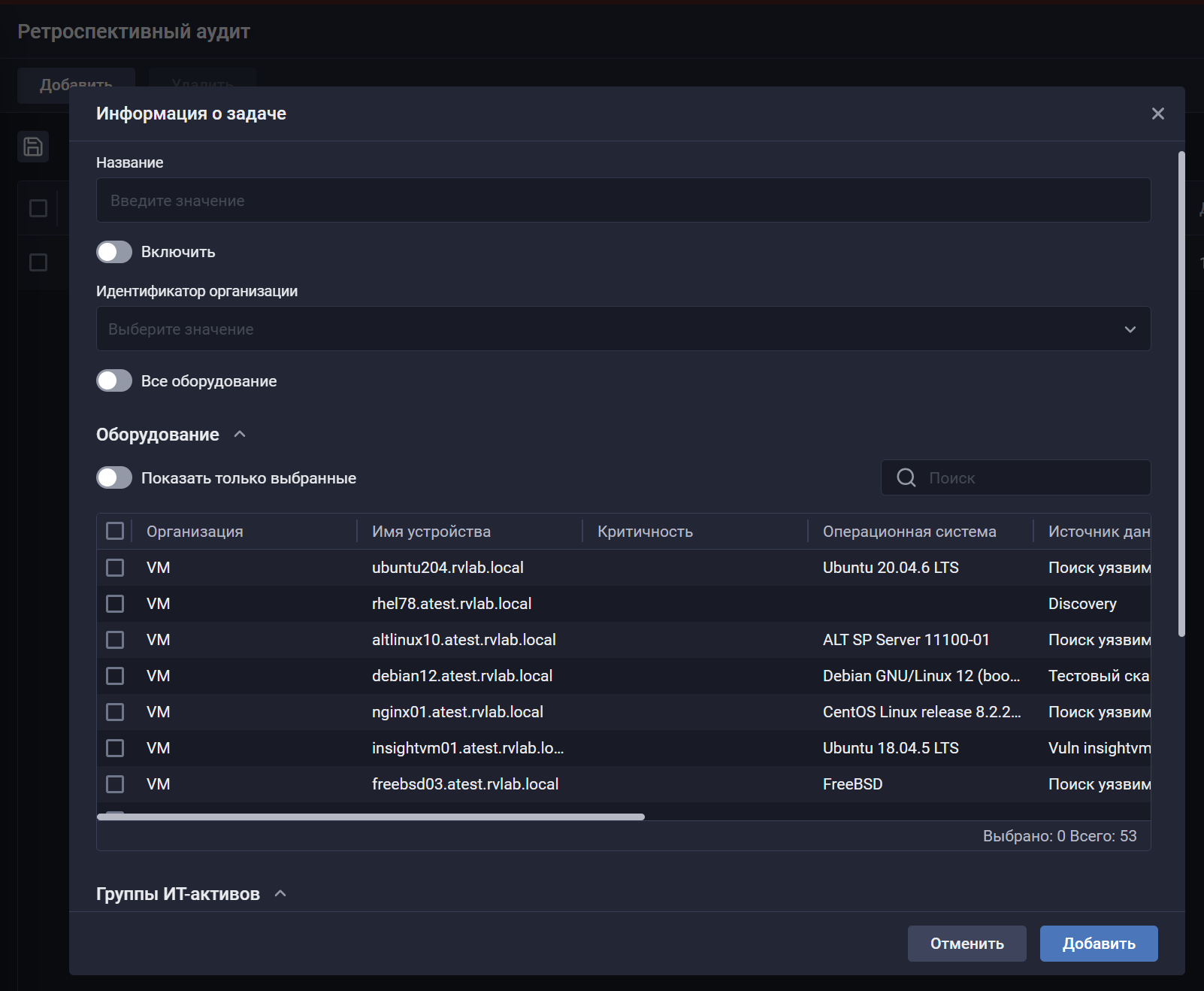
🎯 Поиск уязвимостей без повторного сканирования "Ретроспективный аудит". Представляется как ключевое нововведение версии. Механизм позволяет выявлять уязвимости на основе ранее собранных данных, без запуска повторного сканирования. Фича опциональная. Можно настроить для отдельных хостов, групп хостов или для всех хостов. Запускается по триггерам - обновление базы (сразу пересчитывается по всем указанным целям), по расписанию или вручную.
С технической точки зрения здесь речь идёт о повторной корреляции уже собранных атрибутов активов (например, CPE, версии ПО, установленные пакеты, баннеры сервисов, результаты аутентифицированных проверок, конфигурационные артефакты) с обновлённой базой уязвимостей (в случае R-Vision речь, видимо, идёт о правилах детектирования уязвимостей на OVAL-like языке). За счёт того, что сбор актуальных данных о хосте не производится, новые уязвимости могут быть выявлены практически мгновенно, без нагрузки на сеть и хосты.
Ограничение такого подхода в том, что он строго зависит от полноты и качества ранее собранных данных. Если, например, при последнем сканировании по каким-то причинам не была получена точная версия ПО, то корректный match с новой уязвимостью для этого ПО не получится. Аналогично, любые изменения после последнего скана (установка нового ПО, появление сервиса, изменение конфигурации) не будут учтены. Поэтому ретроспективный аудит — это слой аналитики поверх исторических данных, и он должен работать в связке с регулярным агентным/безагентным сканированием для актуализации данных об активах.
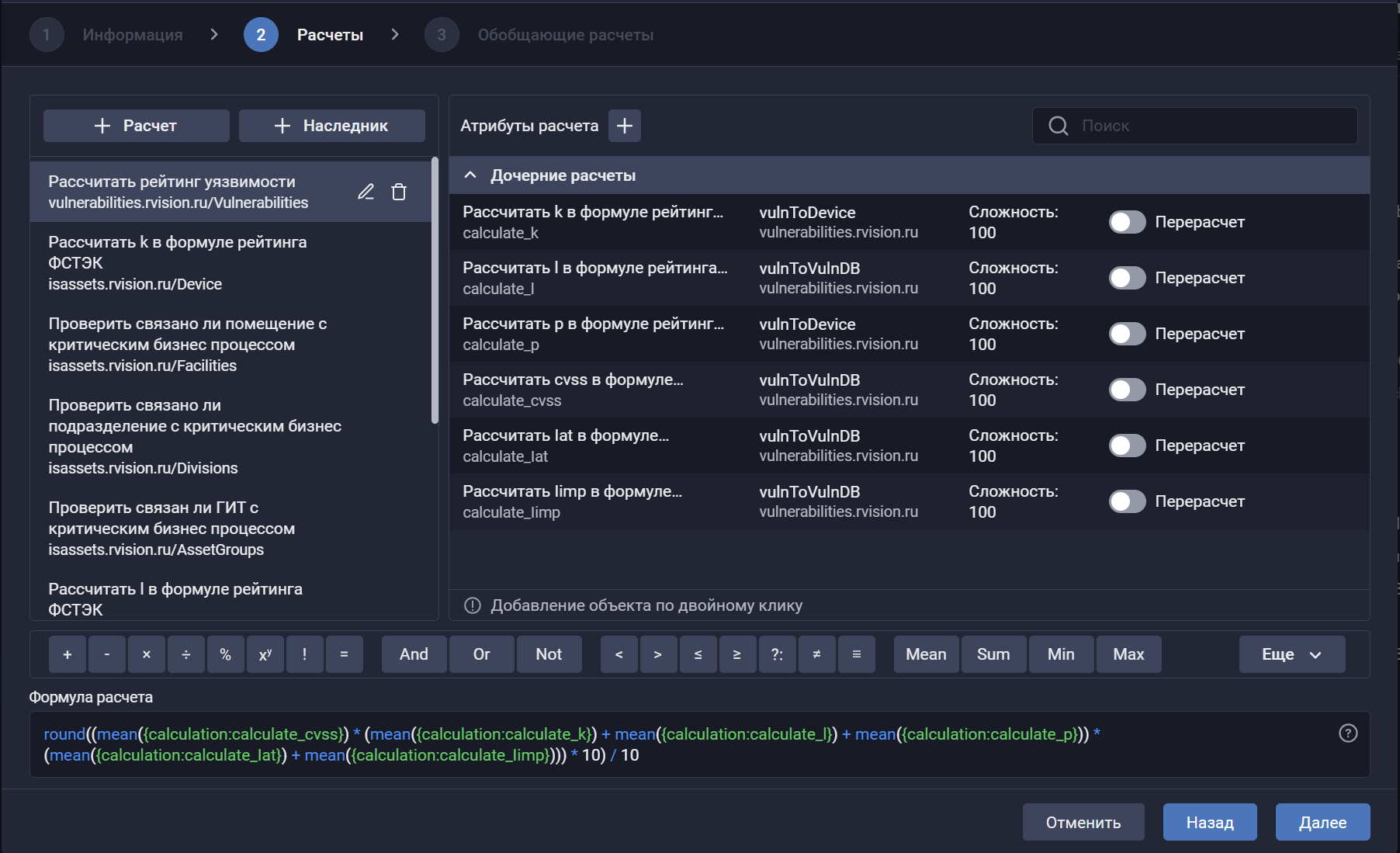
🧠 Графический конструктор расчёта рейтинга уязвимостей. Фича позволяет настраивать формулу приоритизации уязвимостей прямо в интерфейсе, используя атрибуты уязвимости, оборудования или групп ИТ-активов. Формула может учитывать различные типы данных (числовые, текстовые и справочники), что позволяет гибко адаптировать расчёт рейтинга под особенности конкретной ИТ-инфраструктуры.
Пример формулы для расчёта рейтинга уязвимости:
round((mean({calculation:calculate_cvss}) * (mean({calculation:calculate_k}) + mean({calculation:calculate_l}) + mean({calculation:calculate_p})) *
(mean({calculation:calculate_lat}) + mean({calculation:calculate_limp}))) * 10) / 10
Доступны преднастроенные варианты, включая основанный на Методике оценки уровня критичности уязвимостей (ФСТЭК 30.06.2025).
С технической точки зрения это реализация движка кастомного скоринга, где итоговый рейтинг вычисляется через пользовательское выражение, а UI выступает как визуальный конструктор над ним. В формуле используются атрибуты из разных источников (уязвимость, актив, контекст), а пересчёт выполняется автоматически при изменении данных. Это позволяет уйти от статичного CVSS к контекстной приоритизации уязвимости. Однако следует учитывать, что сложность таких моделей быстро растёт, их трудно валидировать и поддерживать, а итоговое качество напрямую зависит от полноты и актуальности данных об активах и уязвимостях.
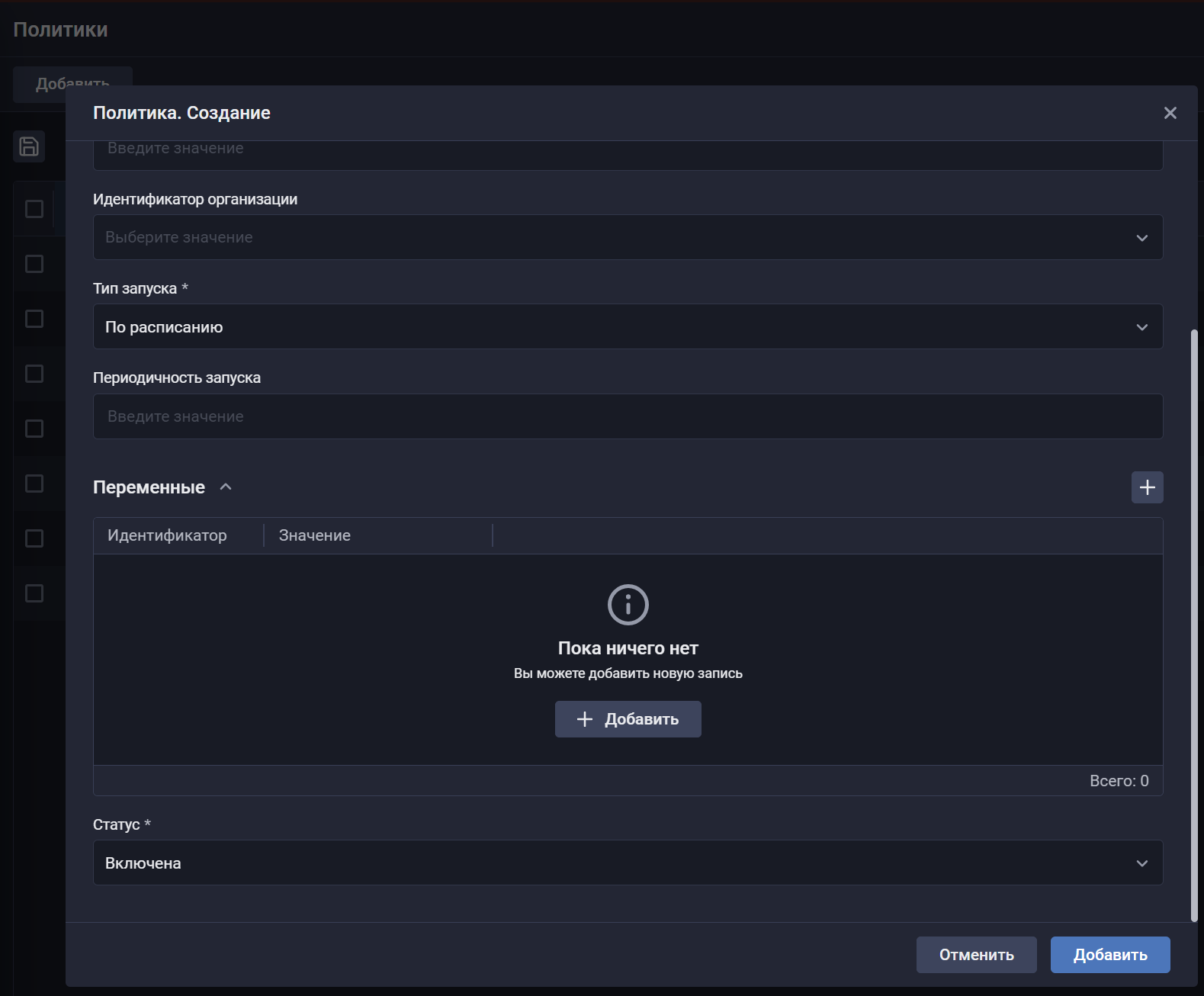
⚙️ Новый механизм политик управления активами и уязвимостями. Он позволяет задавать правила, которые автоматически срабатывают при наступлении заданных условий (по событию или по расписанию). Заявляется, что политики могут изменять атрибуты любых объектов системы или выполнять нужные действия: например, создавать задачу на устранение уязвимости при ее появлении, менять статус актива при обновлении данных или автоматически переводить уязвимость в нужную категорию на основании ее параметров. Поддерживается работа со всеми полями объектов. Это позволяет реализовывать сложные пользовательские сценарии – как в части управления уязвимостями, так и при построении ресурсно-сервисных моделей активов.
По сути, это слой автоматизации поверх модели данных системы. Ценность - в снижении ручной работы и стандартизации процессов. Ограничения - сложность управления большим числом правил, риск конфликтов и неочевидной логики, а также зависимость от качества и консистентности данных.
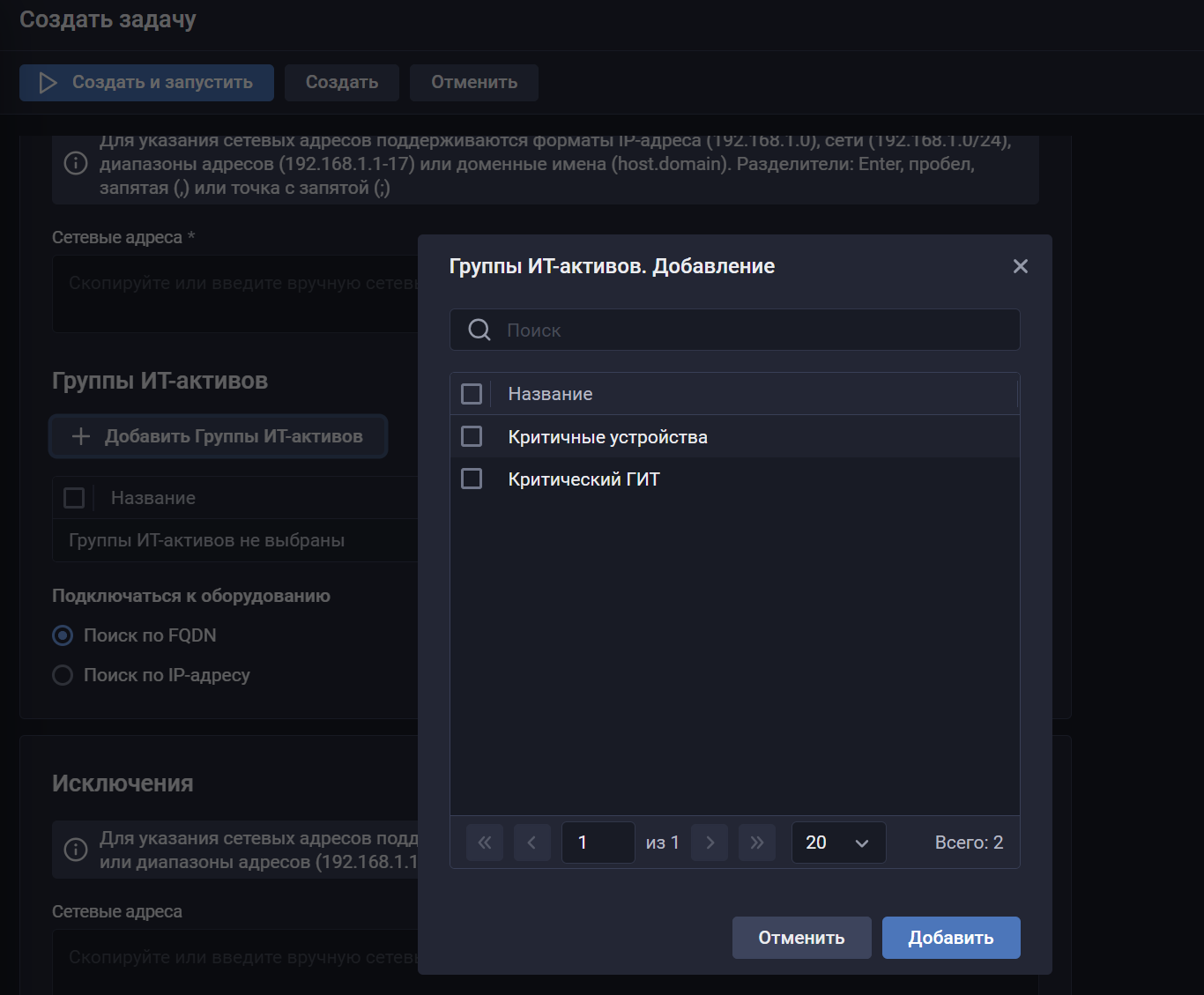
📂 Сканирование групп IT‑активов. Теперь группы IT‑активов можно использовать в задачи сканирования (как в списке целей, так и в исключениях). Состав таких групп может автоматически изменяться, что позволяет использовать одну задачу для актуальных групп активов и упрощает организацию процесса сканирования. Пример групп активов со скриншота: "Критичные устройства", "Критический ГИТ". Сканирование выполняется по IP или FQDN хоста.
Ценность - снижение операционных затрат и уменьшение ошибок. Ограничения - зависимость от корректности группировки: при ошибках в логике формирования групп возможны пропуски или избыточное сканирование, а также меньшая предсказуемость состава целей в конкретный момент времени.
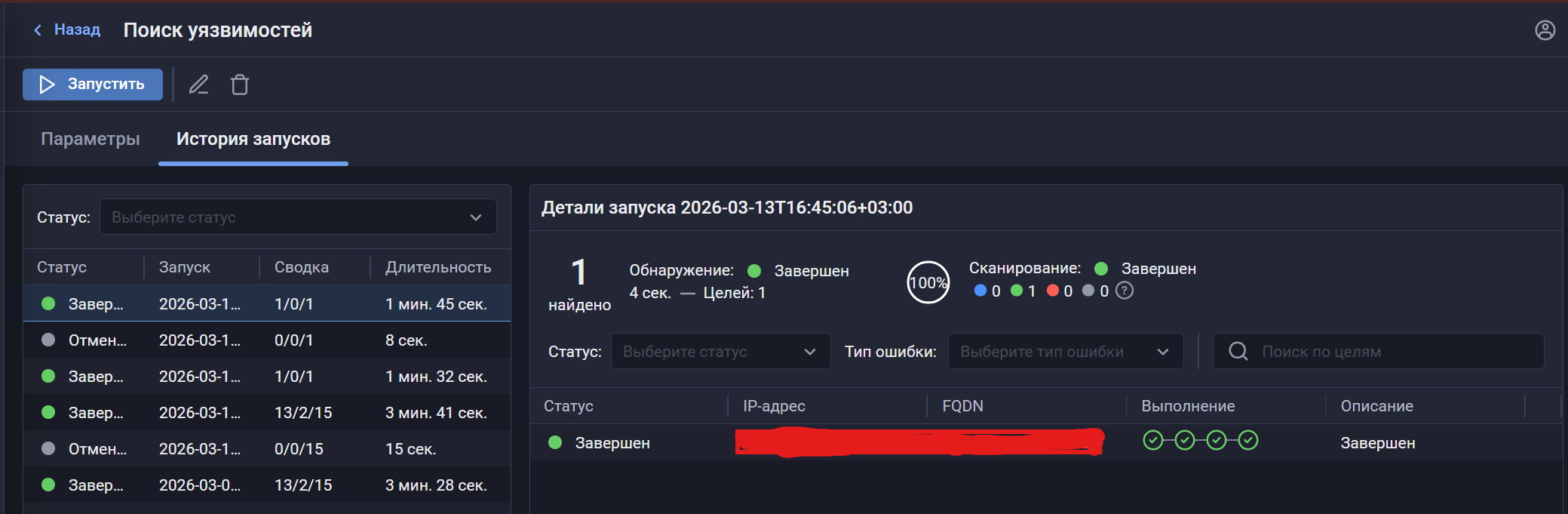
📊 Улучшение информативности карточки задачи сканирования. Туда добавили статистику выполнения, отображение прогресса и ошибок подключения или сбора данных, что упрощает диагностику и контроль хода сканирования.
На последнем скриншоте можем видеть историю запусков. Для запуска показывается статус (завершён/отменён), статистику выполнения сканирования по целям, четырёхсегментный индикатор для статуса сканирования каждого таргета. Довольно симпатично. 🙂
⏱️ Настройка работы агентного сканирования. Появилось настраиваемое расписание, позволяющее задавать периодичность и время сбора данных.
Это должно помогать оптимизировать нагрузку на сеть и хосты. Интересно, как обрабатываются ситуации, когда синхронизация агента с сервером по каким-то причинам невозможна. Агент будет ждать следующего запуска по расписанию или выполнит синхронизацию ASAP?
📊 Улучшение информативности интерфейса. Добавлены полноэкранные карточки оборудования и уязвимостей, расширен набор отображаемых параметров, поддерживается перевод полей уязвимостей на русский язык, улучшены фильтры и представление данных.
В целом, по описанию все фичи выглядят интересно. Ждём демо. 🙂











