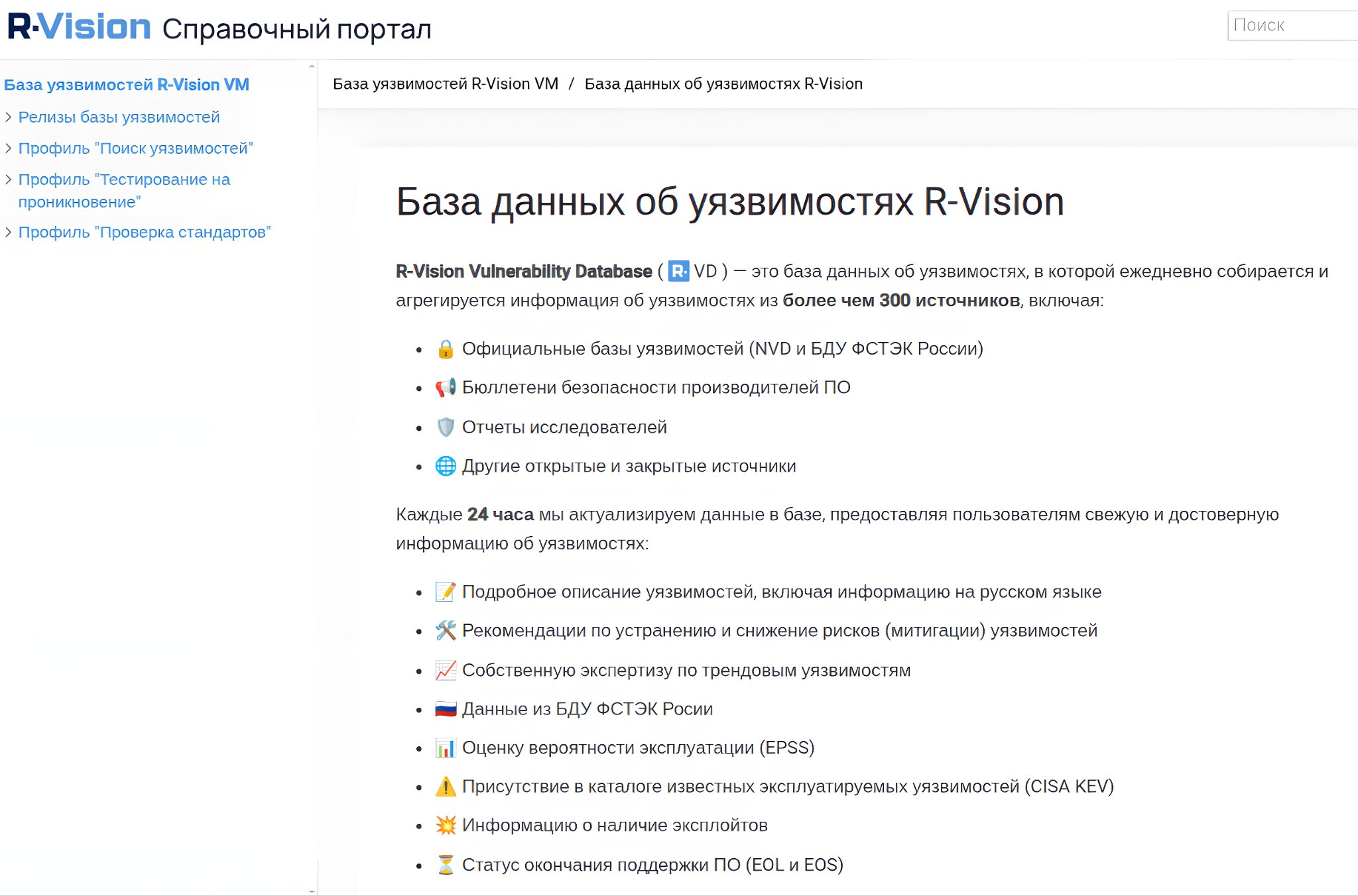
R-Vision раскрыли информацию о продуктах, поддерживаемых R-Vision VM, в новом разделе справочного портала.
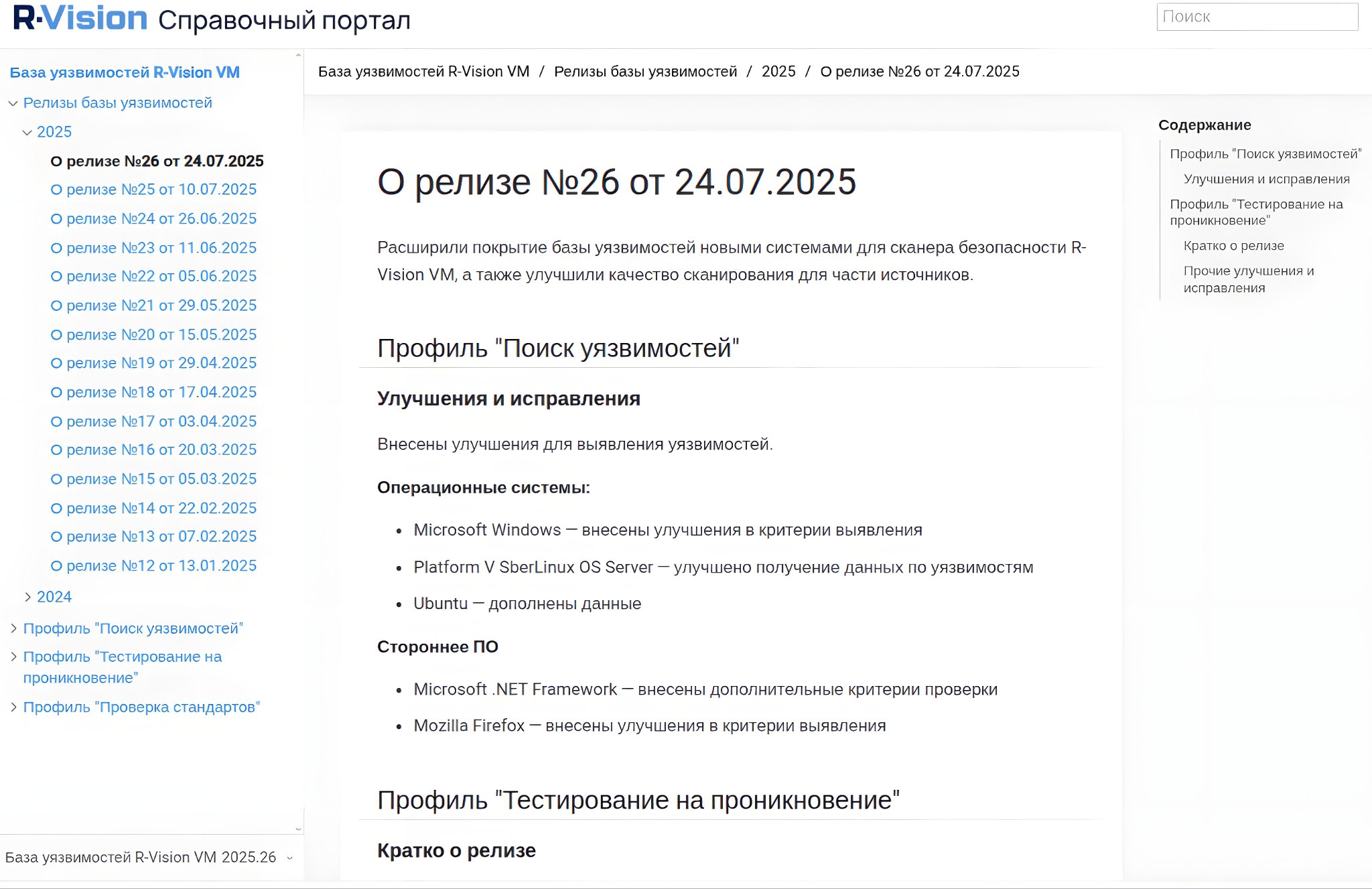
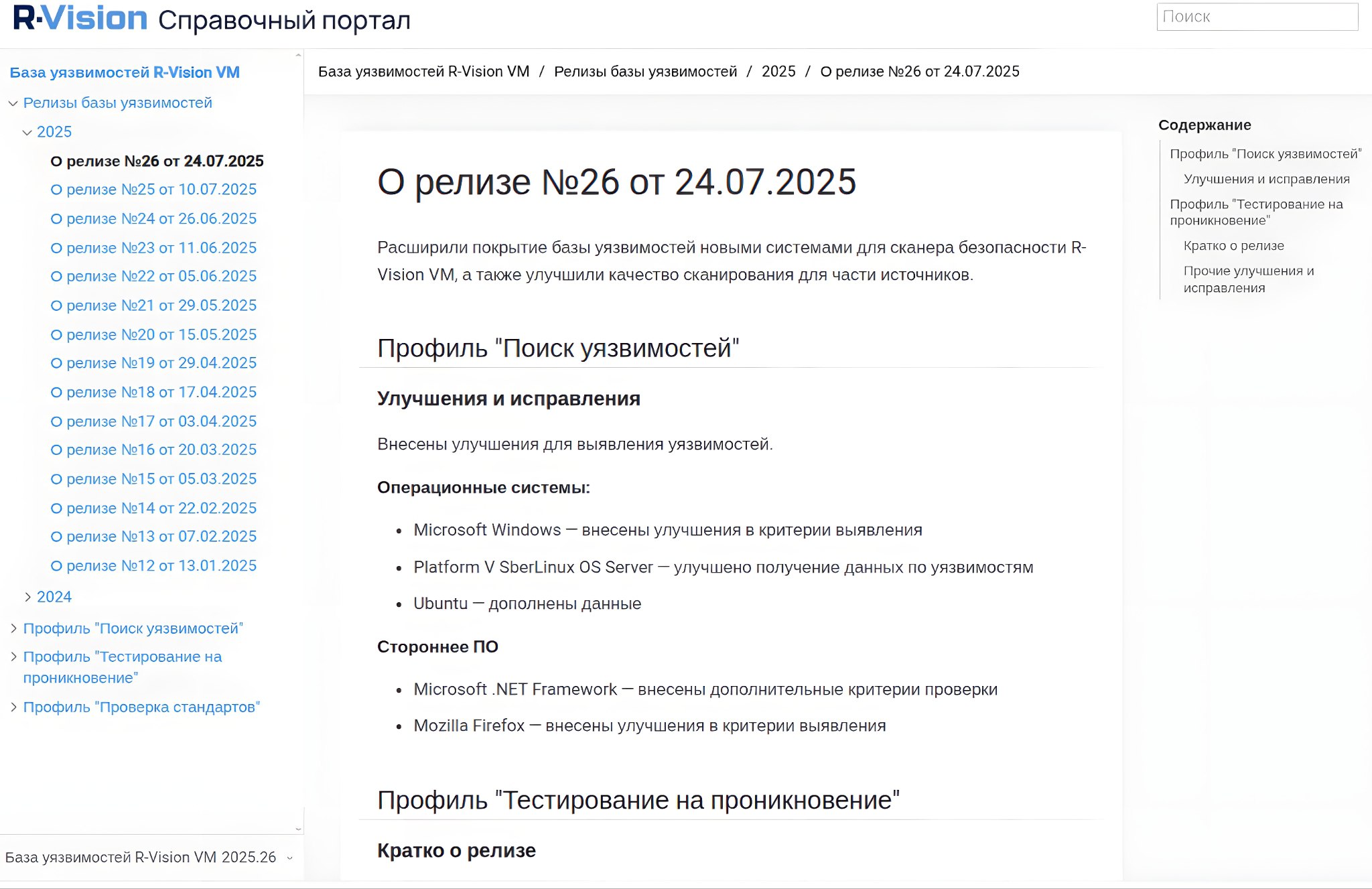
📰 В "Релизах базы уязвимостей" описываются обновления базы уязвимостей с 1 июля 2024 года (выходят 2 раза в месяц). Для уязвимостей, детектируемых в pentest-режиме, приводятся CVE-идентификаторы.
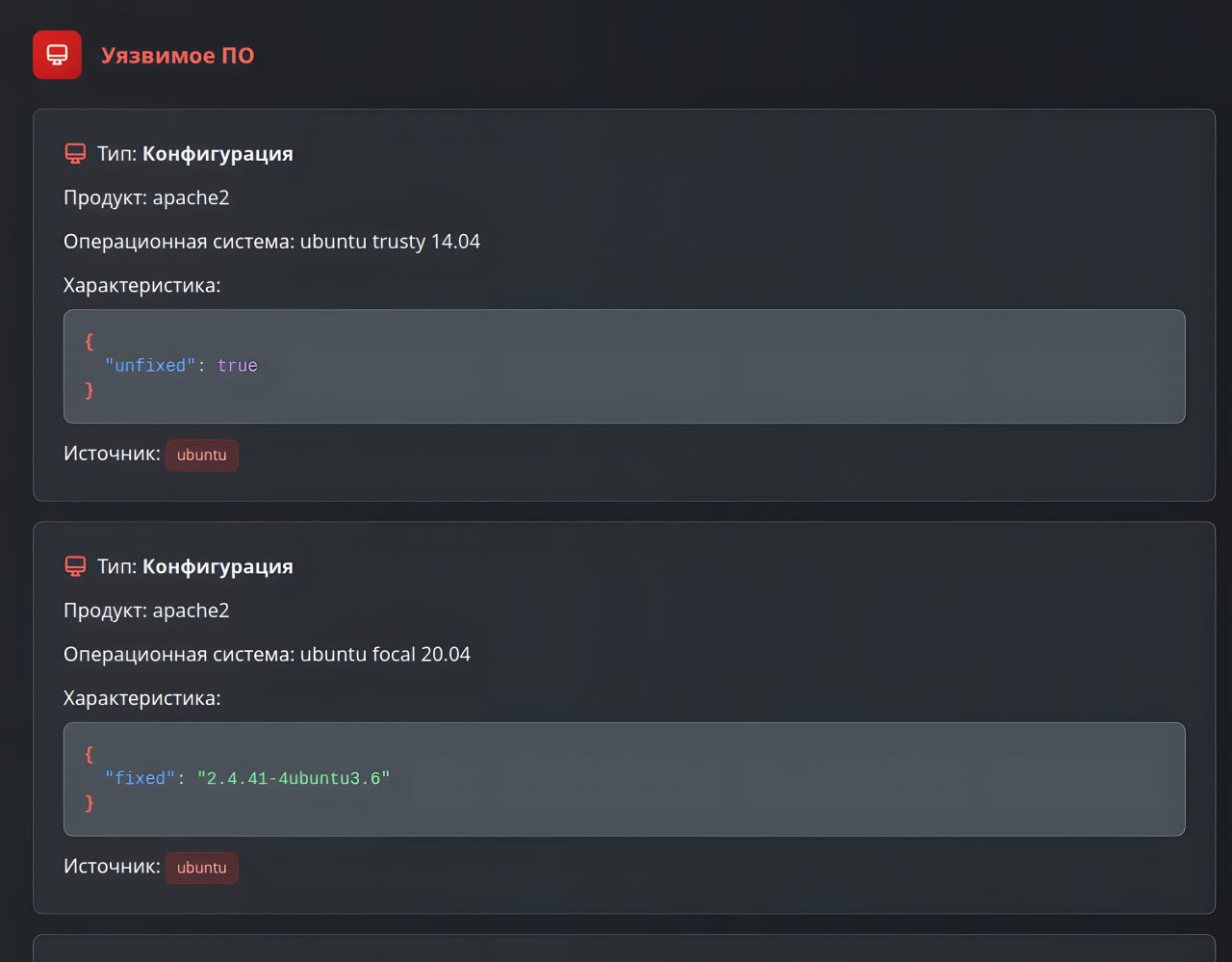
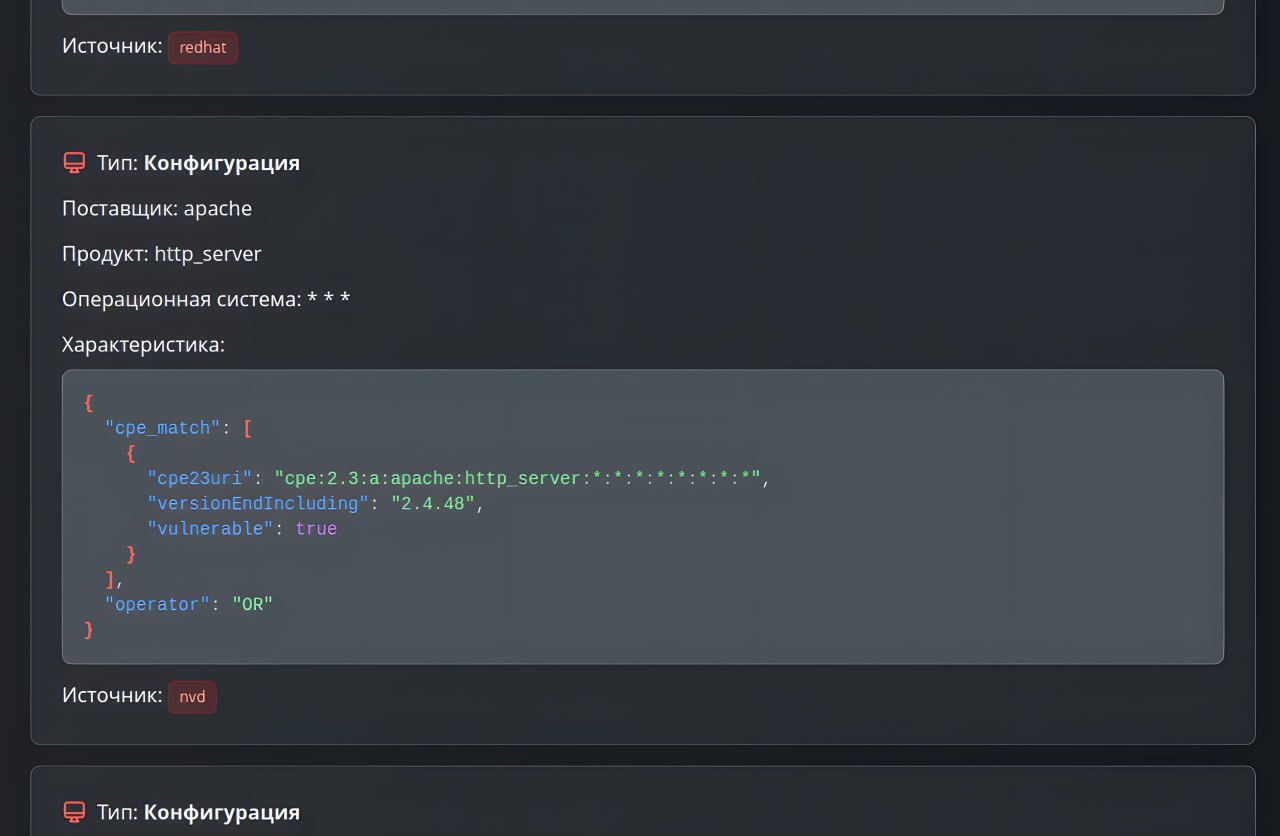
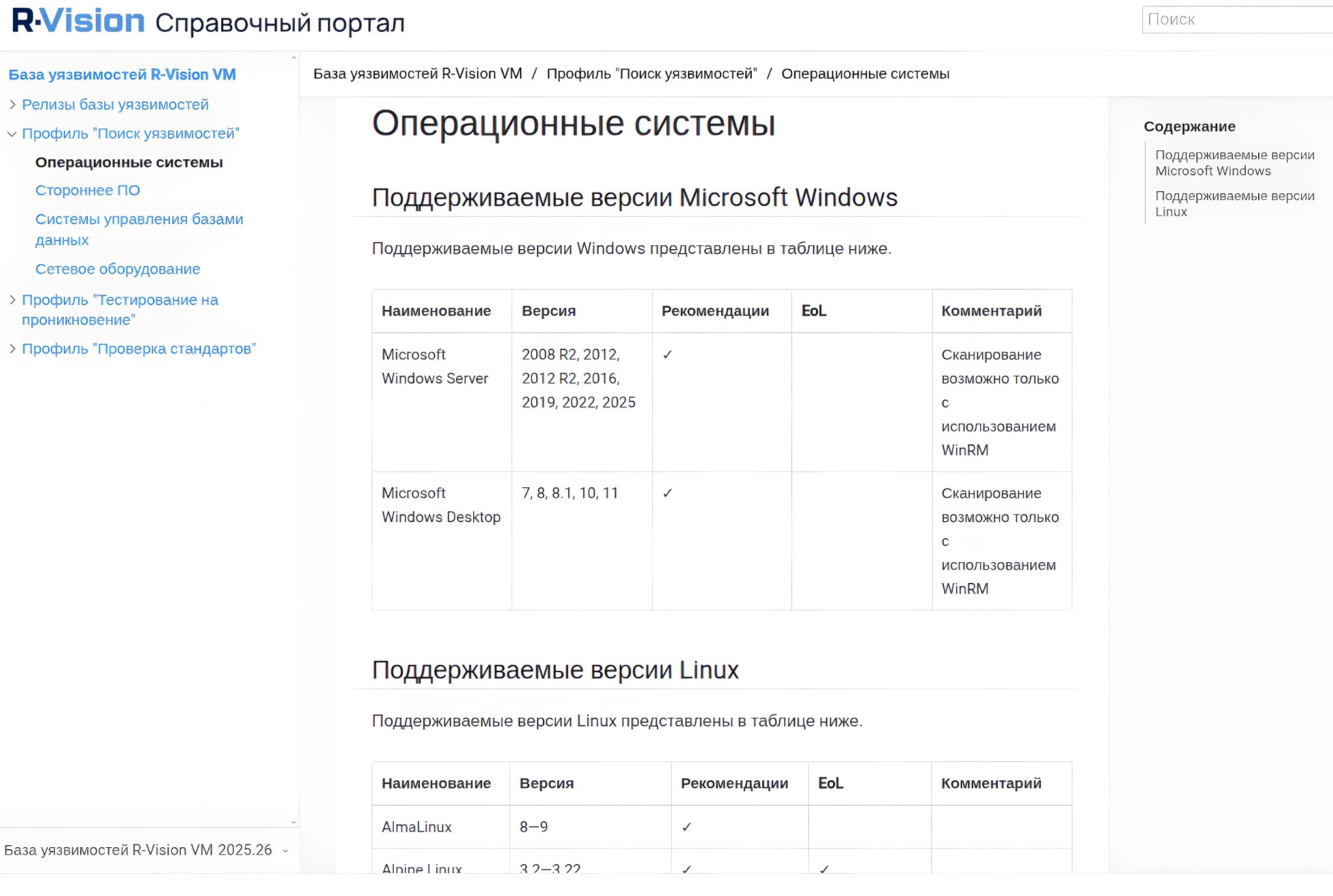
👁 Текущее состояние базы детектов уязвимостей (мисконфигураций) в ОС, стороннем ПО, СУБД и сетевом оборудовании отображается в контексте профилей сканирования:
🔸 Поиск уязвимостей. Параметры: Наименование, Версия, Рекомендации [по устранению уязвимостей], EoL [поддерживается ли версия продукта вендором], Комментарии [об ограничениях детектирования].
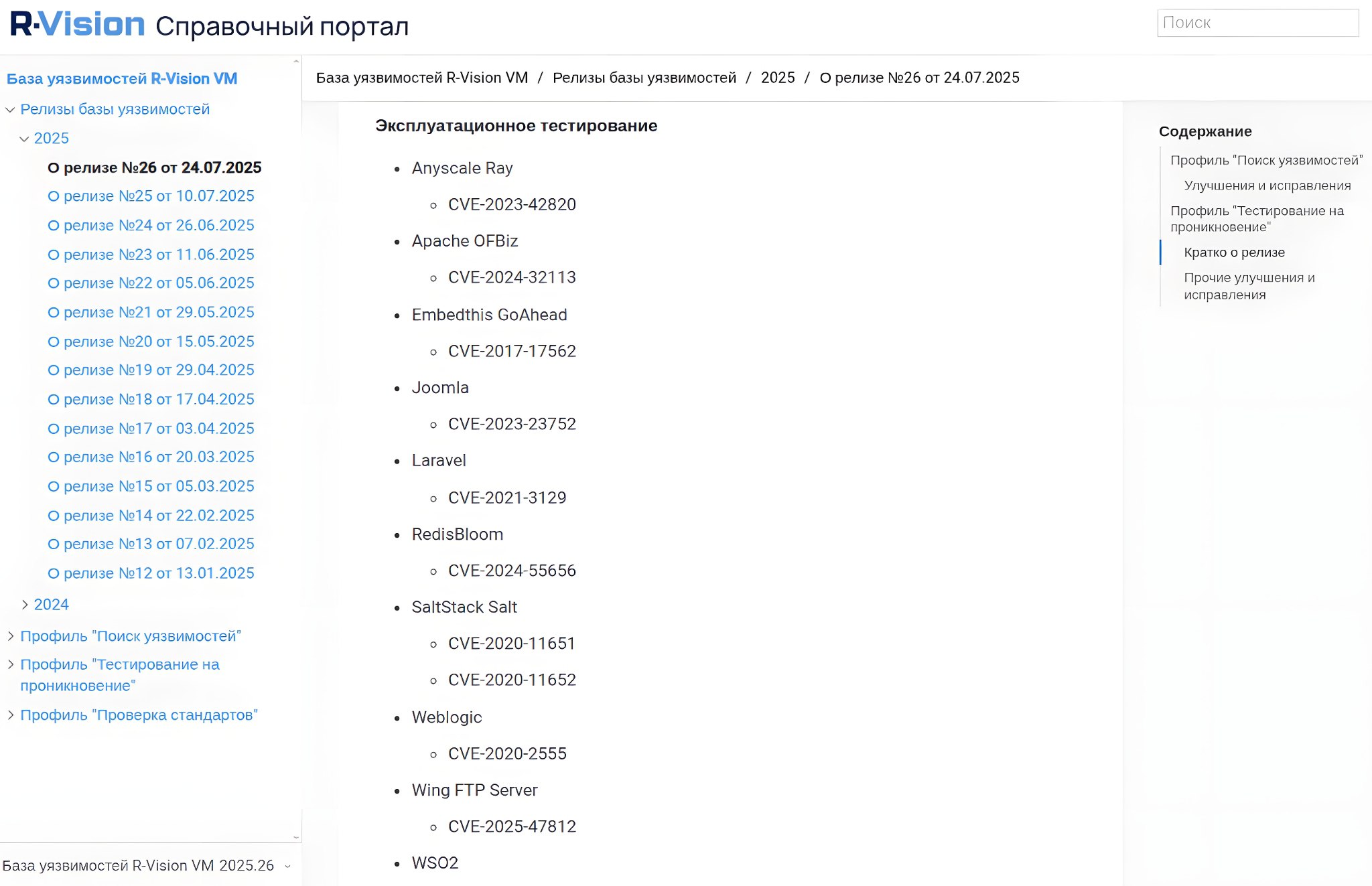
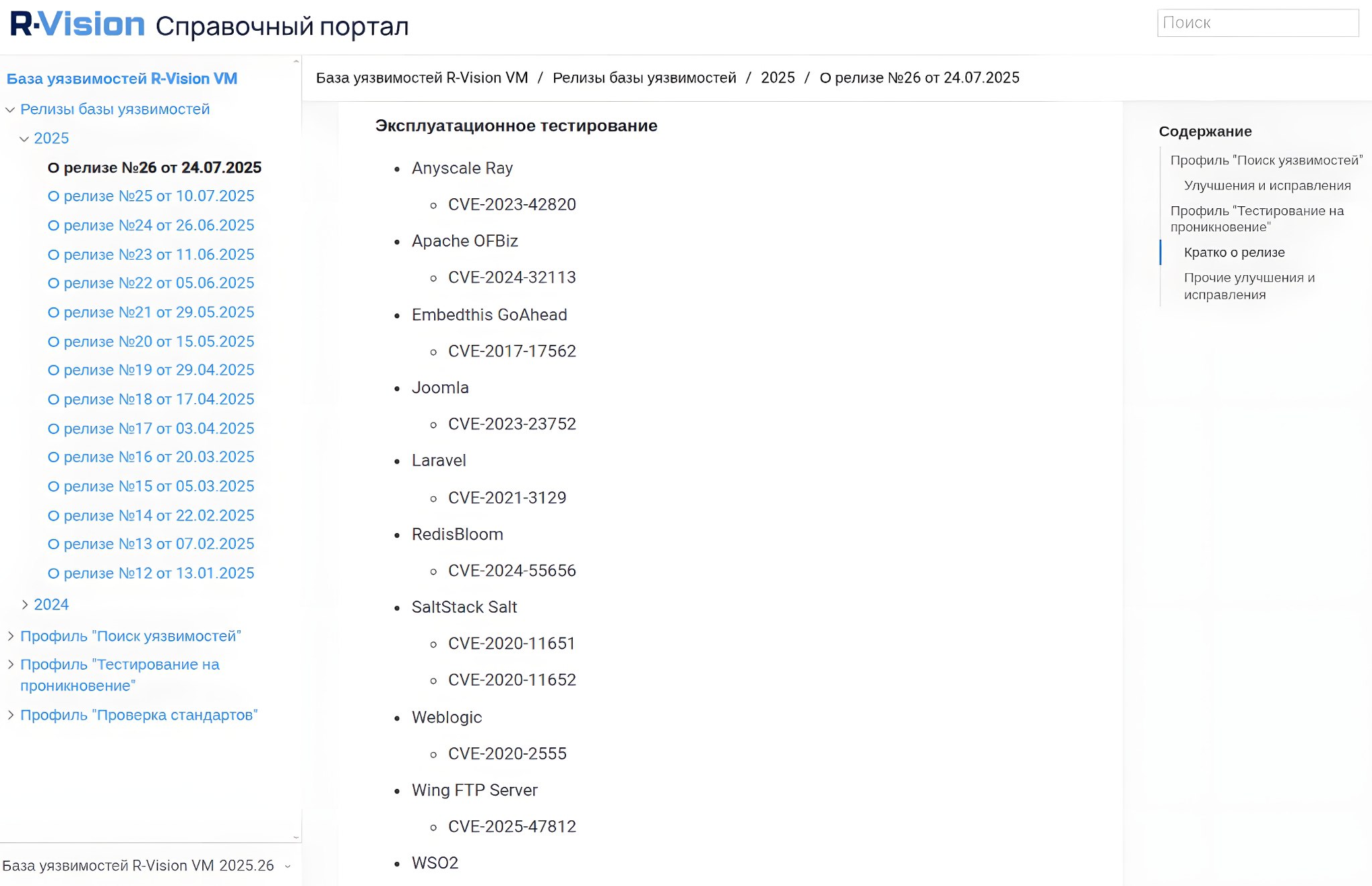
🔸 Тестирование на проникновение. Параметры: Наименование, Обнаружение продукта, Поиск уязвимостей по версии, Сбор дополнительной информации, Подбор учётных данных, Эксплуатационное тестирование.
🔸 Проверка стандартов. Параметры: Наименование и Версия.
Здорово, что эта информация теперь в паблике! 👍👏🙂