Вышел драфт "Методики оценки показателя состояния технической защиты информации и обеспечения безопасности значимых объектов критической информационной инфраструктуры Российской Федерации". Что там с Управлением Уязвимостями?
Есть 2 показателя безопасности, зависящие от оперативности устранения уязвимостей:
🔸 3.2. "На устройствах и интерфейсах, доступных их сети Интернет, отсутствуют уязвимости критического уровня опасности с датой публикации обновлений (компенсирующих мер по устранению) в банке данных угроз ФСТЭК России, на официальных сайтах разработчиков, иных открытых источниках более 30 дней"
🔸 3.3 "На пользовательских устройствах и серверах отсутствуют уязвимости критического уровня с датой публикации обновления (компенсирующих мер по устранению) более 90 дней (не менее 90% устройств и серверов)"
❓Во втором случае не указано откуда дату публикации обновления брать. Наверное нужно сделать единообразно.
❓"доступных их сети Интернет" - опечаточка, "из".
Из пунктов следует, что нужно:
🔻 покрывать все активы детектами уязвимостей
🔻 понимать какие именно активы опубликованы в Интернет
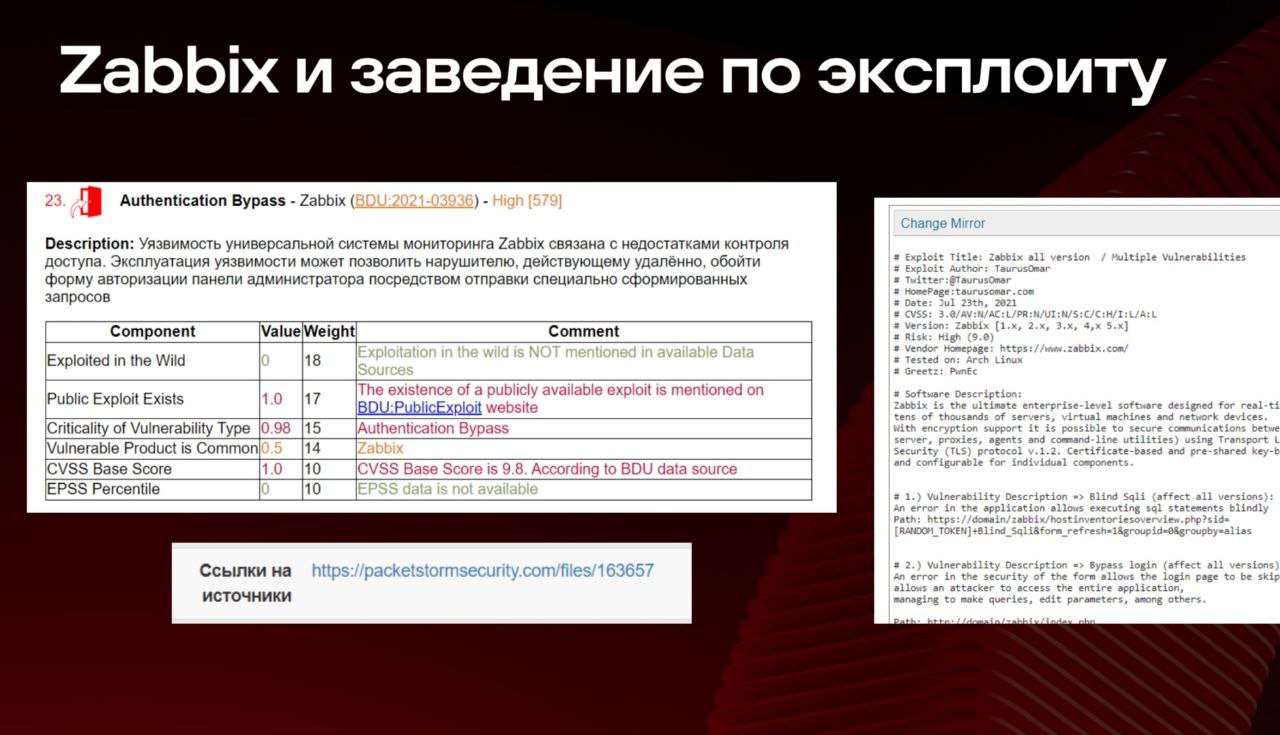
🔻 уметь оценивать критичность уязвимостей по методике ФСТЭК
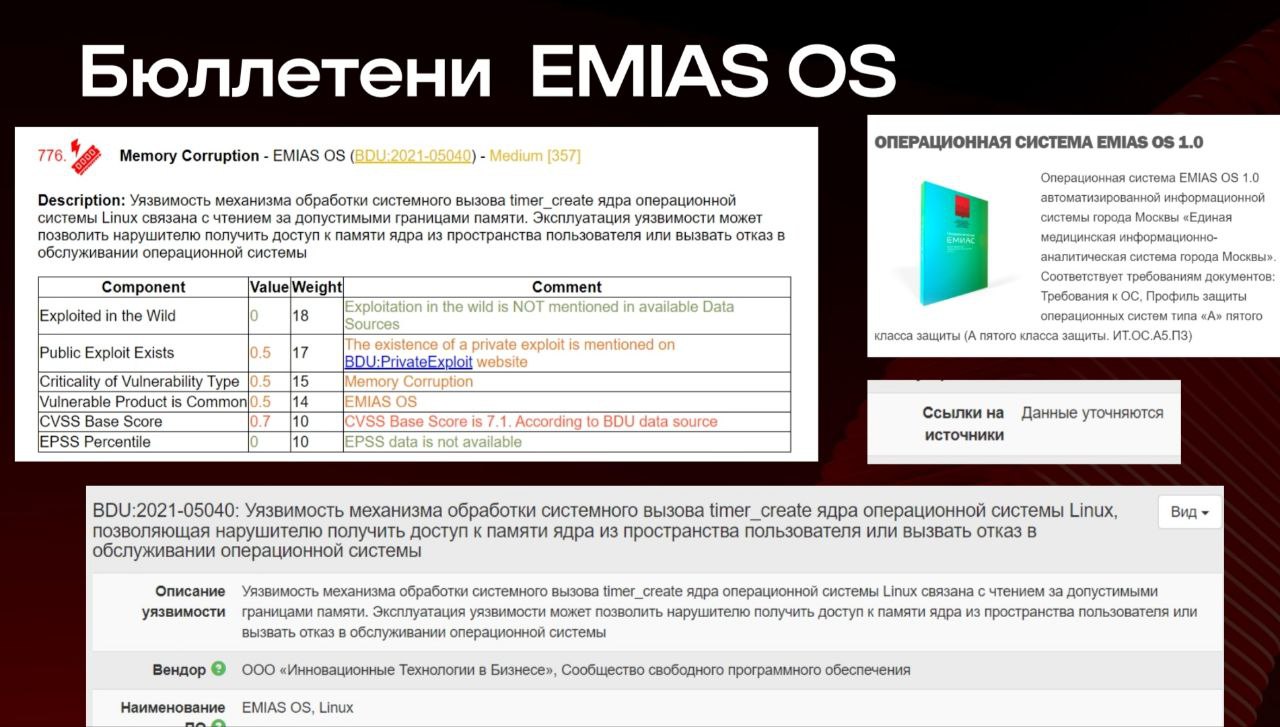
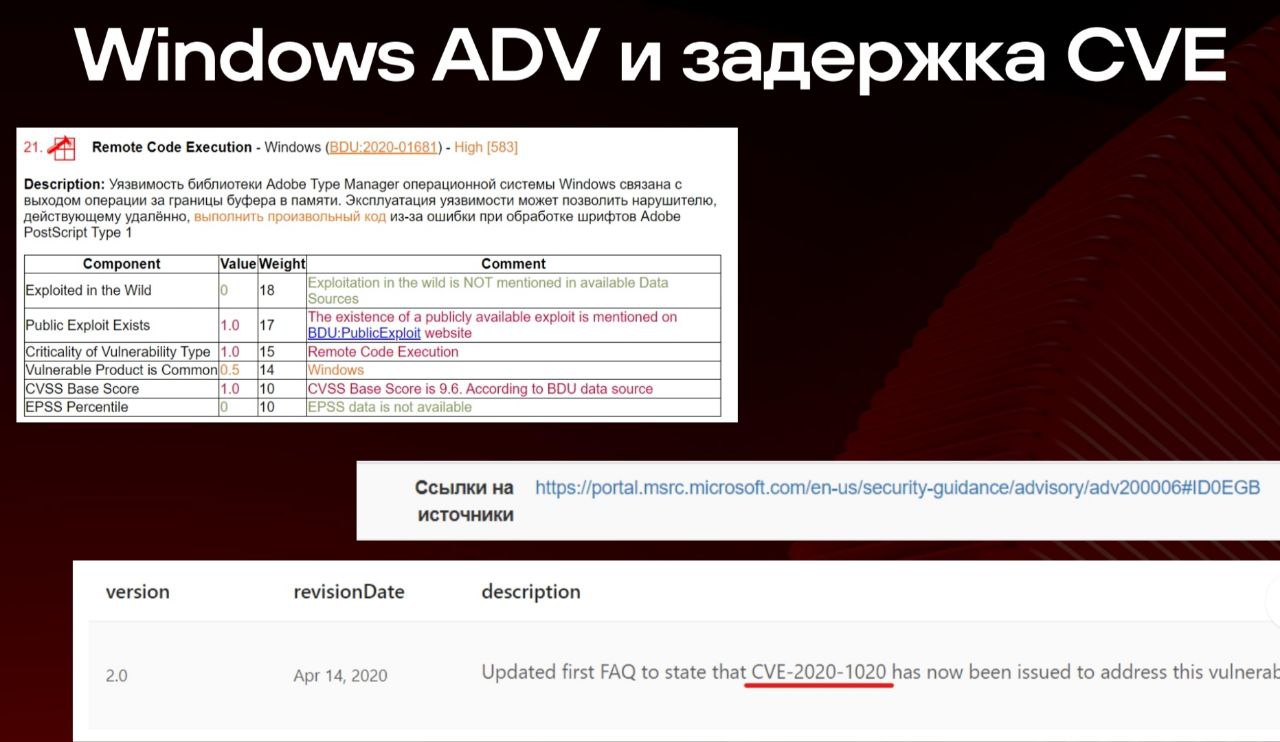
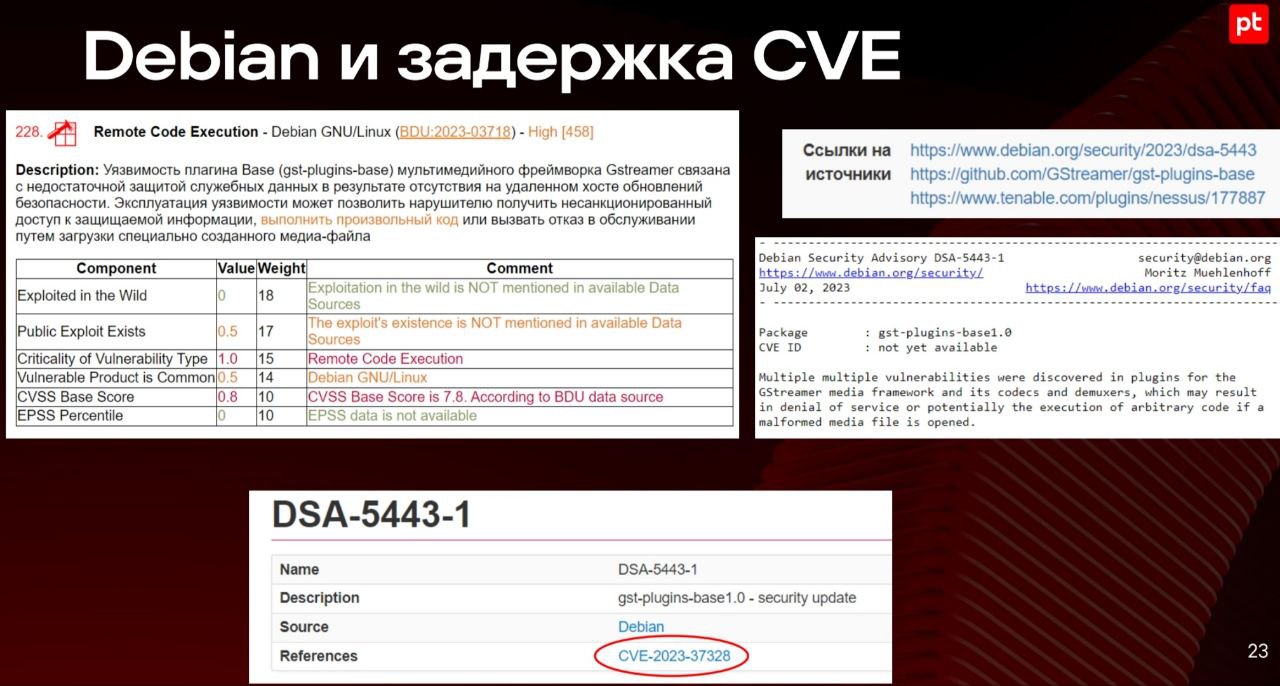
🔻 отслеживать дату публикации обновления (а не дату публикации самой уязвимости!) в разных источниках 😲
Последнее выглядит как нетривиальная задача, т.к. общего реестра данных по обновлениям не наблюдается, получается ведение такого реестра и наполнение его ляжет на организацию. На практике, скорее всего, придется ориентироваться именно на дату публикации уязвимости, т.к. её гораздо проще определять (непосредственно в NVD/BDU) и, по идее, она должна быть всегда более ранней или равной дате публикации обновления. 🤔 Поэтому, возможно, имеет смысл подкрутить формулировочку, например на "дата публикации уязвимости или обновления (компенсирующих мер по устранению)". И сделать пометочку, что допустимо взять наибольшую из имеющихся дат.
И, в идеале, хотелось бы ещё видеть аналог CISA KEV с непосредственно указанными датами, когда конкретные уязвимости должны быть исправлены.